
Bundling forces in money laundering detection using MPC
Banks are involved in a rat race: while criminals are becoming smarter at money laundering, regulatory authorities enforce banks to catch more of them. An individual bank has a too narrow view of all transactions to outsmart these lawbreakers. Can secure Multi-Party Computation allow banks to bundle forces and to fight money laundering collaboratively?
Money laundering: an expanding issue on a global scale
Money laundering is a growing issue: the number of caught money launderers has doubled from 2016 to 2021. It is estimated that between 2 and 5% of the global GDP is laundered each year, which totals a staggering 715 billion to 1.87 trillion euros each year worldwide.
To tackle this, national and international legislative parties are drafting stricter laws each year to enforce banks to enhance their anti-money laundering abilities. Punishments for banks who fail to act on this are severe: in 2021, 5.4 billion dollars of fines were given to banks globally who did not adhere to these anti-money laundering laws.
Expanding the view of banks by Multi-Party Computation
The main challenge banks encounter in anti-money laundering is their limited view of the total set of transactions. Money laundering usually consists of transferring the illegally obtained funds across different accounts, after which the funds are redirected to another account. An example of such a money-laundering pattern can be seen in the figure below. If one were to look at the network of all transactions, such patterns can be spotted relatively easily. However, due to privacy regulations, a single bank can only view transactions involving accounts they hold. This hides a significant portion of all the transactions to each bank and makes spotting such patterns significantly harder.
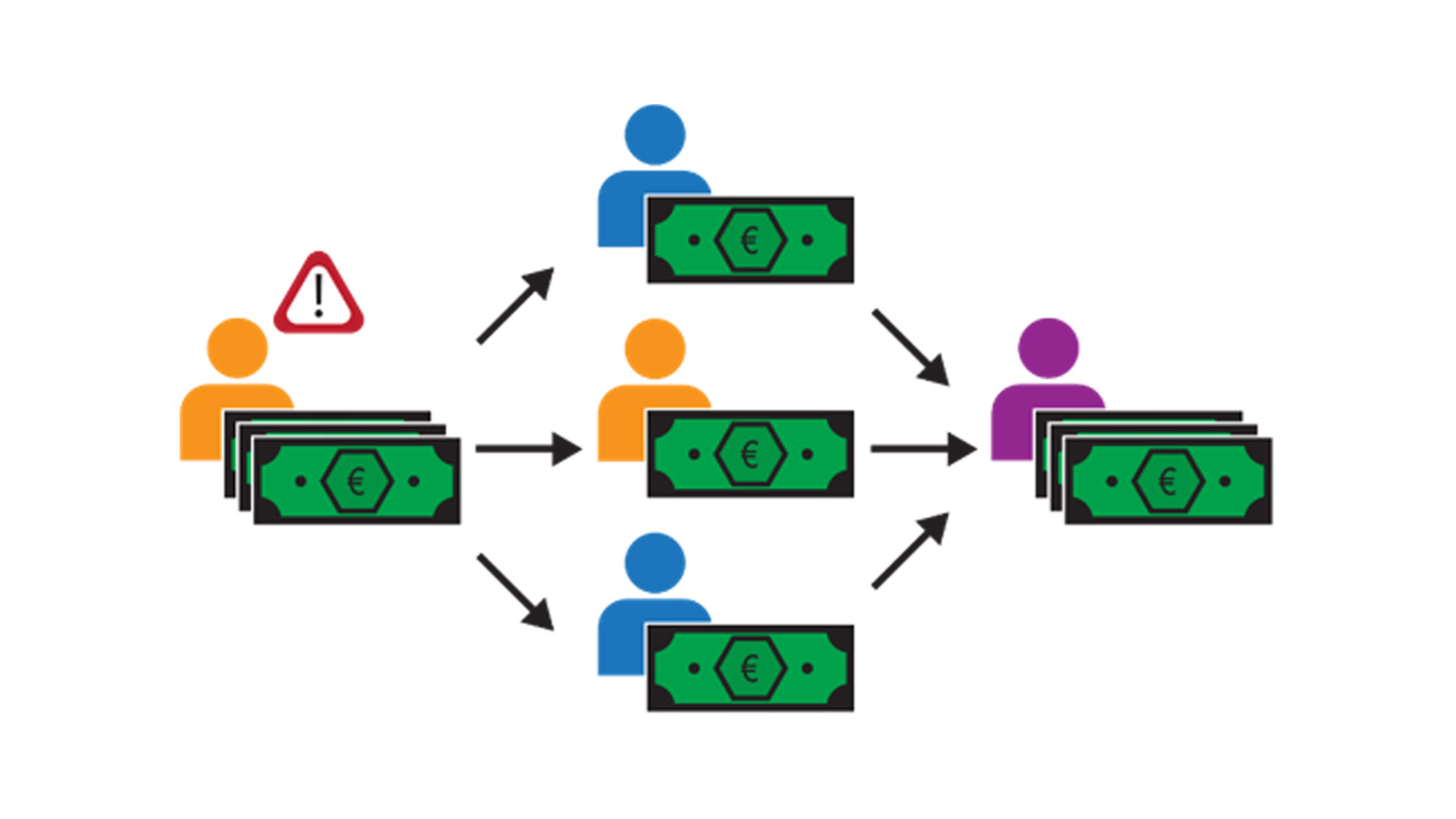
With the rise of innovative techniques such as Multi-Party Computation (MPC), it is natural to ask the following question: can cryptography be used to mitigate this privacy issue and hence aid in the detection of money laundering? This is exactly the question the Alliance for Privacy-Preserving Detection of Financial Crime (APPDFC) addresses. APPDFC is a consortium of the banks ABN AMRO, Rabobank and De Volksbank; transaction monitoring organisation TMNL; and knowledge institutes CWI and TNO. Together, they combine the “fighting financial crime” knowledge of banks with the cryptographic knowledge of CWI and TNO to formulate concrete solutions to the above problem. Within this consortium, various solutions are explored, and this blog post explains the findings from the graph embeddings use case.
Graph embeddings: applying machine learning methods on graphs
Graph embeddings form a family of methods driven by the desire of applying machine learning on graphs. Transaction data can be represented in the form of a transaction graph. In this, accounts are represented by nodes and transactions between the accounts are represented by edges. In addition, each node contains certain attributes, for example its cashflow or its geographical location. Both the accounts, transactions and attributes are privacy-sensitive information. For our use case of money laundering detection, we would want a machine learning algorithm that detects instances of money laundering.
Compared to other data structures, graphs are rich in information: they contain information about nodes, links, local and global structure information. Common machine learning methods cannot easily handle such structured data and that is where graph embeddings come into play. They circumvent this issue by generating a graph embedding for each node of the graph, which is a vector yielding a summary of all the relevant information concerning the node. Depending on the application, different characteristics of the node are highlighted, for example its own attributes, its local neighbourhood, or its role in the global graph. These vectors can then be used to apply standard machine learning methods on, such as linear regression, to indirectly apply machine learning on graphs
There are various methods to create such graph embeddings, each of which is suitable for different use cases. For our use case of money laundering detection, we require one with the following characteristics:
- It should be able to process graphs with many nodes, as transaction graphs contain tens of millions of nodes;
- It should consider the many node attributes transaction graphs have;
- It should be an inductive method, meaning that it can be applied to previously unseen graphs. This is important as transaction graphs change by the day;
- It should give neighbouring nodes a similar graph embedding, as one’s involvement with money laundering is strongly correlated with their neighbour’s involvement.
From all graph embedding methods in the literature, GraphSAGE is best suited for our use case, as it satisfies all the above requirements.
GraphSAGE: learning your role in a graph by sampling and aggregating
GraphSAGE works by the two basic principles of SAmpling and aGgrEgating. For each node, we start by sampling its neighbours, after which we aggregate the attributes of these sampled neighbours. By applying these two principles twice in a layered approach, we end up with a graph embedding for each node. From the construction, we see that the graph embedding contains a randomly generated summary of the local neighbourhood of the specific node. For an in-depth overview of the protocol, we point the reader to the original publication of GraphSAGE on arxiv.
Secure GraphSAGE: the future of money laundering detection?
We began with testing the suitability of GraphSAGE for our use case. To recap: we wish to enhance the detection of money-laundering by applying machine learning on the full transaction graph. To do this, we run GraphSAGE on the full transaction graph to generate a graph embedding for each account, which can then be used in a standard machine learning model. As the full transaction graph contains much more data than the view of any individual bank, it is expected that this increase of data leads to a better detection of money laundering.
Indeed, first results on practice graphs similar to real transaction graphs showed promising results. Using GraphSAGE increased the accuracy of a 2-class classification from 0.58 to 0.78 compared to using attributes only. However, such an implementation of GraphSAGE is not possible in the case of money laundering, as GraphSAGE requires sharing of privacy-sensitive attributes and subsequent computations with them. Luckily, applying GraphSAGE with MPC can, in theory, remove these barriers. By running GraphSAGE on encrypted attributes, these attributes can be shared and computed with freely. With high hopes, we implemented a so-called Secure GraphSAGE implementation using the Paillier encryption library from TNO.
Although this resulted in a working implementation and interactive demonstrator, we ran into severe scalability issues. While the generation of a single graph embedding without MPC takes less than a second, generating the same graph embedding in the encrypted domain took anywhere from thirty to ninety minutes. Doing this for the millions of nodes at a single bank gives overheads too large to be considered feasible. Even with high-performance computers, it would take months to do a single run of GraphSAGE in a practical setting.
Reasons for overhead and lessons learned
The main cause of this overhead is the considerable number of attributes the nodes of the practice graphs had (>1400). Because we decided to encrypt each feature separately, this gave massive overheads in the number of encryptions. Standard transaction graphs contain much fewer attributes (<50), so that an application of Secure GraphSAGE on transaction graphs would be significantly faster. It would be interesting to see how GraphSAGE would perform on practice graphs with a similar number of attributes. In addition, there exist cryptographic techniques such as packing and vector addition chains which can speed up algorithms in which vectors of values need to be encrypted. An explanation of these techniques can be found in this article. More research will have to be done to see whether techniques as these above can tackle our overheads.
Nonetheless, we did not manage to implement GraphSAGE in the way that we had hoped. However, this does not mean that we did not benefit from this use case. Specifically, we learned about the possibilities and impossibilities of applications of MPC in such use cases. We have shown that the straightforward implementation of MPC may result in infeasible use cases, where the implementation is not ready to handle such vast amounts of data. Before applying and implementing MPC, we believe that it is important to think about how to apply MPC before blindly applying it. These considerations should involve tests on small examples to gauge what sort of overheads one might expect in a given use case. To do this properly, it is important to start such considerations early in the process, often even before the algorithm without cryptography is fully understood. In this way, potential overheads can be spotted early on and tackled in a suitable and swift fashion. We believe that these are valuable lessons that we can apply for our future use cases.
Conclusions
The GraphSAGE use case shows that MPC can indeed aid in the detection of money laundering. However, a straightforward implementation of Secure GraphSAGE lacks scalability and hence has no short-time outlook on real world use. Despite this, we are happy with the results and view it as a Brilliant Failure: although we did not get the result we were aiming for, we have shown the (im)possibilities of MPC for use cases like this one. In addition, we learned from the current shortcomings and know how important it is to pay attention to the preparations, design, and small tests in future projects.
Acknowledgements
The research activities that led to this result were funded by ABN AMRO, CWI, Rabobank, TMNL, De Volksbank and PPS-surcharge for Research and Innovation of the Dutch Ministry of Economic Affairs and Climate Policy, and TNO's Appl.AI programme.
Contact us
-

Sarah van Drumpt
Functie:Researcher Cyber Security and Public HealthSarah van Drumpt is a consultant in the Applied Cryptography and Quantum Algorithms department. She manages a portfolio of projects related to sense-making with sensitive data. Her work is focused on the adoption of innovations that strengthen the digital society while simultaneously safeguarding important societal values such as privacy and autonomy.
-
Email:Email Sarah
-
Get inspired
Poverty reduction can be made more effective with data analysis

LANCELOT: new collaboration between IKNL and TNO
