Collaboration with TNO
Creating innovations is a matter of working together, and that requires partners. That is why, every year, we team up with some 3,000 large multinationals, SMEs, universities and public-sector organisations within and outside the Netherlands to tackle challenges.
How we work
Knowledge development is a joint endeavour. That is something we notice every day at TNO. That is why companies, public-sector bodies and other organisations frequently work with us. And we are keen to work with these parties. The collaboration takes many forms, such as projects on commission, public private partnerships, technology transfer, partnerships via associations and Joint Innovation Centres (JIC's). Interested in finding out how we can work with you?

Projects on commission
If there is something you would like to have researched for your company, public-sector organisation or foundation, you can commission a research project. We will make agreements with you about the work, the cost, and the exclusivity of the results.
Public-private partnerships
Companies and public-sector and social organisations can also work with us in public-private partnerships, which can take the form of a short-term project or a long-term program.


Startups, scaleups and SMEs
TNO Fast Track is TNO's platform for startups, scaleups and SMEs, i.e. entrepreneurs. TNO Fast Track enables you to access the specialist knowledge of our 3500 experts, more than 50 labs and testing facilities, and our extensive network.
TNO Ventures
TNO Ventures is committed to turning technological innovations into practical solutions for urgent societal challenges. By launching spin-offs and helping startups through the crucial development phase, we accelerate the journey from research to widespread application, ensuring that groundbreaking technologies quickly and effectively reach their full potential.

Innovation centres
By leveraging the shared expertise of companies, governments, and knowledge institutions, innovation centers provide the ideal environment for groundbreaking projects, from technological breakthroughs to sustainable solutions.
International
Research and innovation do not stop at national borders. We can only strengthen the knowledge base of the Netherlands if we work closely with leading international knowledge partners, companies and governments.

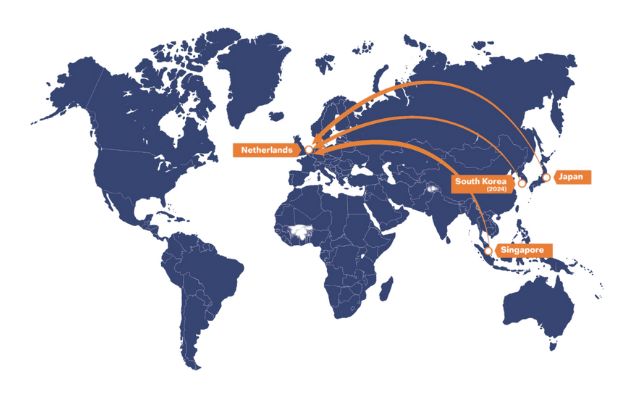
TNO in the APAC region
Certain organisations in APAC are valuable partners for TNO's vision on achieving the Three Zeros: Zero Calamities, Zero Emissions, and Zero Loss. In APAC, TNO recognises many topics of mutual interest, and similar if not higher urgency, to tackle the challenges of tomorrow.
Contact us
-

Erik Drop
Function not known-
Standplaats:Den Haag - New Babylon
-
Email:Email Erik
-